
Table of Contents
- The Moment Everything Changed
- The Problem Nobody’s Talking About
- Normal Software: The Old World
- AI Software: The New World
- The Side-by-Side Comparison
- What This Means for Product Teams
- The Hybrid Architecture: How to Actually Build Products
- The New Developer Skills (And What PMs Need to Know)
- Practical Frameworks for PMs
- Common Mistakes (And How to Avoid Them)
- The Future: What’s Coming Next
- Key Takeaways: What Every PM/Founder Needs to Remember
- Your Action Plan: What to Do This Week
- Final Thoughts: We’re All Learning
- What’s Next?
- Let’s Keep the Conversation Going
- Resources & Further Reading
The Moment Everything Changed
Three months ago, I asked my engineering lead a simple question during sprint planning:
“How long will the AI feature take to build?”
He paused. Then said something that changed how I think about product development forever:
“I don’t know. This isn’t like building normal software. The rules are completely different.”
That’s when I realized: We’re managing two fundamentally different types of software with the same playbook.
And it’s causing massive miscommunication, blown timelines, and frustrated teams.
After dozens of conversations with engineers, AI researchers, and fellow PMs, I’ve mapped out exactly what’s different—and why it matters for anyone building products in 2025.
The Problem Nobody’s Talking About
Here’s what’s happening in product teams right now:
- PMs are writing feature specs the same way they always have
- Engineers are using old mental models for new technology
- QA teams are testing AI features like they test normal features
- Stakeholders are expecting predictability where none exists
Everyone’s speaking different languages, but we’re all pretending we understand each other.
The result?
- Features that miss the mark
- Testing that doesn’t catch real issues
- Deployment nightmares nobody anticipated
- User experiences that feel “off”
The root cause: AI software is architecturally different from normal software. Not just “a bit different”—fundamentally, structurally, conceptually different.
Let me show you what I mean.
Normal Software: The Old World
Let’s start with what we know. Here’s how traditional software works:
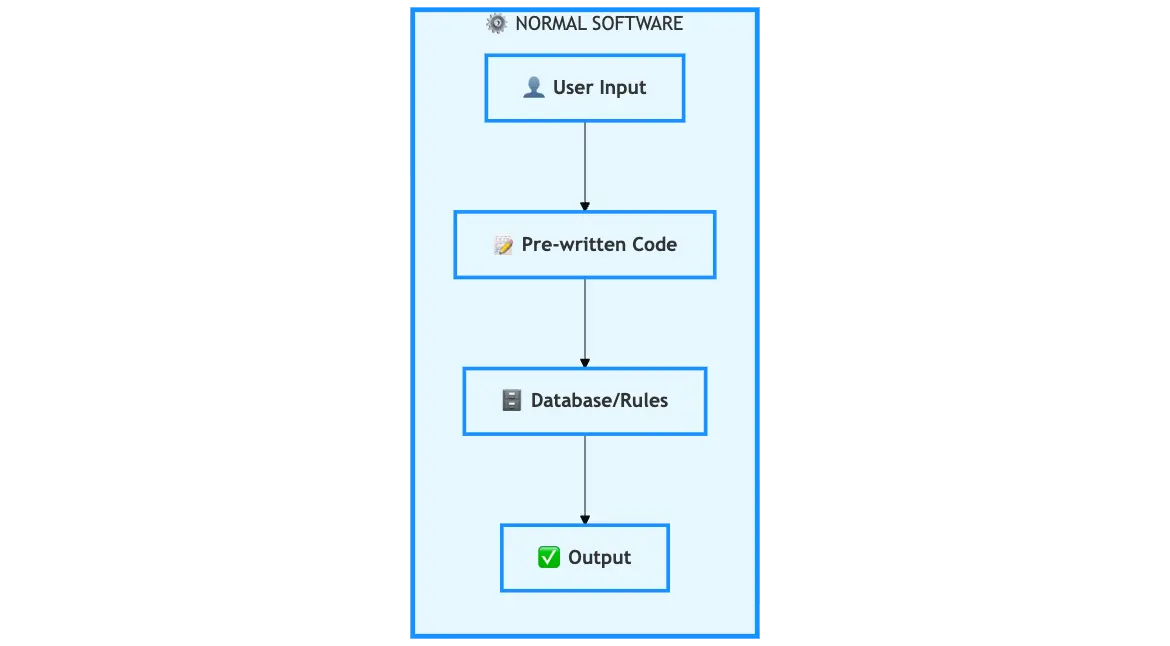
The Architecture
User Input → Pre-written Code → Database/Rules → Output
It’s beautifully simple:
- User provides input (clicks a button, submits a form)
- Code executes predetermined logic (if/else statements, functions)
- System queries rules or database (fetch data, apply business logic)
- System returns output (confirmation, result, error message)
Key Characteristics
Deterministic: Same input = same output, every single time.
Predictable: You can trace every decision through the code.
Rule-based: All logic is explicitly written by developers.
Controllable: If something breaks, you find the bug and fix it.
Real Example: E-commerce Checkout
Let’s say you’re building a checkout flow:
// Deterministic code
function processCheckout(cart, user) {
if (cart.total > 0) {
if (user.hasPaymentMethod()) {
const order = createOrder(cart, user);
chargePayment(user.paymentMethod, cart.total);
sendConfirmation(user.email);
return { success: true, orderId: order.id };
} else {
return { success: false, error: "No payment method" };
}
}
return { success: false, error: "Empty cart" };
}
What’s happening:
- Every decision is pre-defined
- Every path is traceable
- Every outcome is predictable
- Every error is handleable
As a PM, you can spec this precisely:
Acceptance Criteria:
✓ When user clicks "Complete Order" with valid cart
→ System processes payment
→ System creates order in database
→ System sends confirmation email
→ User sees success message
✓ When user clicks "Complete Order" with no payment method
→ System shows error: "Please add payment method"
→ User redirected to payment page
This is the world we’re all comfortable with.
But AI software? Completely different game.
AI Software: The New World
Now let’s look at how AI software (specifically, Large Language Models using token generation) actually works:
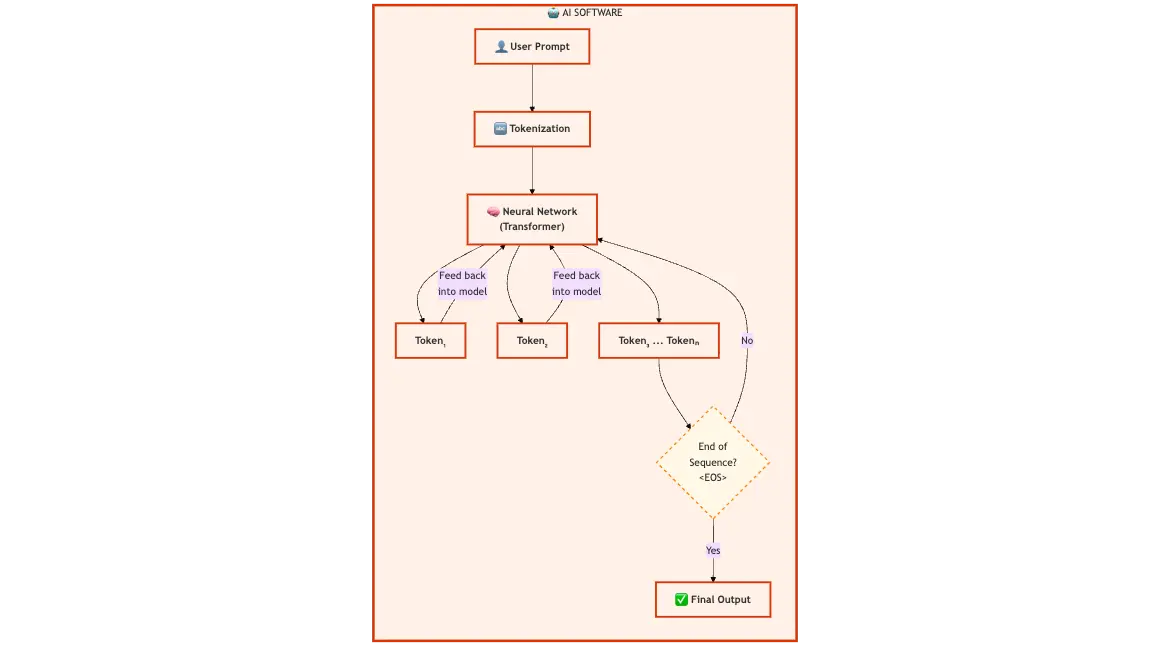
The Architecture
User Prompt → Tokenization → Neural Network (Transformer)
→ Feed back into model → Token₁
→ Feed back into model → Token₂
→ Feed back into model → Token₃
→ ... (continues until End of Sequence)
→ Final Output
This is not just a different implementation—it’s a fundamentally different paradigm.
How Token Generation Actually Works
Let me break this down step-by-step because this is where most PMs (including me, initially) get confused:
Step 1: User Prompt
User types: "Write a professional email declining a meeting"
Step 2: Tokenization
The text gets broken into tokens (roughly word pieces):
["Write", "a", "professional", "email", "declining", "a", "meeting"]
Step 3: Neural Network Processing
The model (a massive neural network called a Transformer) processes these tokens through hundreds of layers, creating a mathematical representation of the meaning.
Step 4: Token Generation (The Magic Part)
Here’s where it gets wild:
The model generates ONE token at a time, probabilistically.
First token generation:
- "Dear" (40% probability)
- "Thank" (30% probability)
- "Hi" (15% probability)
- "I" (10% probability)
- ... (thousands of other possibilities)
Model picks: "Thank"
Then, that token gets fed back into the model:
Input now: [original prompt] + ["Thank"]
Next token generation:
- "you" (60% probability)
- "You" (20% probability)
- "the" (10% probability)
- ...
Model picks: "you"
This continues, token by token:
"Thank" → "you" → "for" → "the" → "invitation" → "," → ...
Until the model generates an “End of Sequence” token, signaling it’s done.
Key Characteristics
Autoregressive: Each token depends on all previous tokens.
Probabilistic: Same input ≠ guaranteed same output. There’s always randomness.
Generative: The model creates new content, not just retrieving or calculating.
Context-dependent: Small changes in the prompt can radically change outputs.
Real Example: AI Email Assistant
Let’s say you’re building an AI feature that helps users write emails:
User prompt: "Write a professional email declining a meeting request"
What happens behind the scenes:
Token 1: "Thank" (generated)
Token 2: "you" (generated, influenced by Token 1)
Token 3: "for" (generated, influenced by Tokens 1-2)
Token 4: "the" (generated, influenced by Tokens 1-3)
Token 5: "invitation" (generated, influenced by Tokens 1-4)
...
Token N: <END_OF_SEQUENCE>
Final output might be:
“Thank you for the invitation to meet. Unfortunately, I won’t be able to attend due to schedule conflicts. I appreciate you thinking of me and hope we can connect another time.”
But here’s the thing: Run the same prompt again, and you might get:
“I appreciate the meeting request, but I’m unable to join at this time. My schedule is fully committed this week. Let’s find another opportunity to connect soon.”
Same input. Different output. Both valid.
As a PM, how do you spec this?
Acceptance Criteria:
✓ When user provides prompt about declining meeting
→ System generates professional email
→ Tone is polite but firm
→ Includes thanks/appreciation
→ Suggests future connection
??? System generates... what exactly?
??? How do we define "correct"?
??? What does "professional" mean to the model?
You can’t specify exact outputs. You can only specify desired behaviors.
This is the fundamental shift.
The Side-by-Side Comparison
Let me put this in a table that shows just how different these architectures really are:
| Aspect | Normal Software | AI Software (Token Gen) | What This Means for PMs |
|---|---|---|---|
| Logic | Written by humans | Learned from data | You can’t “just add a rule”—the model needs retraining or prompt engineering |
| Execution | Code paths | Token generation | Execution is creative, not mechanical. It’s “thinking,” not “calculating” |
| Testing | Unit tests | Prompt alignment | Testing means “does it behave appropriately?” not “does it execute correctly?” |
| Bugs | Logic errors | Hallucinations | Bugs aren’t “broken code”—they’re misaligned behavior or confident wrongness |
| Deployment | Containers/servers | Model weights | Deploying means shipping trained models (GBs of data), not just application code |
| Optimization | CPU scaling | GPU orchestration | Infrastructure needs are fundamentally different and more expensive |
| Versioning | Git releases | Fine-tunes/checkpoints | “Versions” means different training states, not just code changes |
| Debugging | Stack traces | Prompt analysis | No error logs to read—you analyze input/output patterns |
| Performance | Response time | Token latency | Measured in tokens-per-second, not requests-per-second |
| Costs | Server compute | Inference compute | Every request uses expensive GPU cycles |
| Predictability | 100% reproducible | Probabilistically consistent | Same input can produce different outputs (by design) |
Let’s Dig Into Each Row
1. Logic: Written vs Learned
Normal Software:
function calculateShipping(weight, distance) {
if (weight < 1) return 5;
if (weight < 5) return 10;
if (distance > 100) return 15;
return 12;
}
Every rule is explicit. You write it. You control it.
AI Software: The model learned from millions of examples what “appropriate shipping cost” looks like. You can’t see the “rules”—they’re encoded in billions of neural network weights.
PM Impact: When stakeholders say “just make it do X,” you can’t just write a rule. You need to either:
- Retrain the model on new data
- Engineer the prompt differently
- Add guardrails in code around the AI
2. Execution: Code Paths vs Token Generation
Normal Software:
if user.age >= 18:
show_adult_content()
else:
show_family_content()
AI Software:
Model generates next token based on probability distribution
→ No "if/else"
→ No clear decision tree
→ Just: "Given everything before, what token is most likely next?"
PM Impact: You can’t “debug” why the AI chose a particular response by looking at code. You have to analyze patterns, prompts, and model behavior.
3. Testing: Unit Tests vs Prompt Alignment
Normal Software Testing:
def test_checkout():
cart = Cart(total=100)
user = User(has_payment=True)
result = process_checkout(cart, user)
assert result.success == True
assert result.order_id is not None
Pass or fail. Clear expectations.
AI Software Testing:
def test_email_generation():
prompt = "Write professional decline email"
response = generate_email(prompt)
# What do we assert?
# Is it professional? (subjective)
# Is it polite? (subjective)
# Does it decline? (yes, but how?)
# Best we can do:
assert "thank" in response.lower()
assert len(response) > 50
assert toxicity_score(response) < 0.1
PM Impact: Acceptance criteria must shift from “does X” to “behaves like Y” with examples and behavioral boundaries.
4. Bugs: Logic Errors vs Hallucinations
Normal Software Bug:
// Bug: wrong operator
if (price > 100) { // Should be >=
applyDiscount()
}
Find the line. Fix the operator. Done.
AI Software “Bug”:
User: "What's the capital of France?"
AI: "The capital of France is Lyon."
Why? Who knows.
The model confidently generated wrong information.
No "line of code" to fix.
PM Impact: You need strategies for:
- Detecting hallucinations
- Implementing fact-checking
- Setting confidence thresholds
- Building feedback loops
5. Deployment: Containers vs Model Weights
Normal Software Deployment:
docker build -t myapp:v2 .
docker push myapp:v2
kubectl set image deployment/myapp myapp=myapp:v2
You’re shipping code (megabytes).
AI Software Deployment:
# Download model weights
# LLaMa 70B: ~140GB
# GPT-4 equivalent: ~1TB+ (estimated)
aws s3 cp s3://models/llama-70b /models/
kubectl create deployment llama-server --image=llama-runtime
# Configure GPU nodes
# Set up inference endpoints
# Handle rate limiting
You’re shipping trained models (gigabytes to terabytes).
PM Impact:
- Deployment is slower and more complex
- You can’t “hotfix” model behavior
- Version rollbacks mean swapping massive files
- Infrastructure costs are 10-100x higher
What This Means for Product Teams
Okay, so the architectures are different. Why does this matter for you as a PM or founder?
1. Feature Specification Must Change
Old way (Normal Software):
User Story: As a user, I want to filter products by price
Acceptance Criteria:
- When I select "$0-$50" filter, show only products in that range
- When I select "$50-$100" filter, show only products in that range
- When I clear filter, show all products
New way (AI Software):
User Story: As a user, I want AI to help me find products matching my style
Behavioral Requirements:
- Model should understand natural language descriptions
- Responses should be conversational but concise
- Recommendations should reflect stated preferences
- Tone should be helpful, not pushy
Examples of good behavior:
User: "I need a dress for a beach wedding"
AI: "I'd suggest light, flowy fabrics in pastels or tropical prints.
Would you prefer maxi length or something shorter?"
Examples of bad behavior:
User: "I need a dress for a beach wedding"
AI: "Buy product #12847" (too direct, no context)
AI: "Let me tell you about the history of beach weddings..." (too verbose)
Success Metrics:
- User continues conversation (engagement)
- User clicks recommended products (relevance)
- User completes purchase (conversion)
- Low feedback reports (quality)
See the difference?
You’re not specifying outputs—you’re specifying behaviors, boundaries, and examples.
2. Timeline Estimation Gets Fuzzy
Normal software timeline:
Frontend: 2 weeks
Backend API: 1 week
Database schema: 3 days
Testing: 1 week
Total: ~4 weeks
Pretty predictable.
AI software timeline:
Prompt engineering: ??? (could be days or weeks of iteration)
Model fine-tuning: ??? (depends on results, might need multiple rounds)
Evaluation framework: 1 week
Testing with real users: 2 weeks (need qualitative feedback)
Guardrails implementation: 1 week
Total: 6-12 weeks???
Much fuzzier.
Why?
- You don’t know if your prompts will work until you test them
- Model behavior might require unexpected adjustments
- “Good enough” is subjective and requires user feedback
- No clear “done” state—just “good enough for launch”
PM Impact: Build in buffer time. Use iterative releases. Set behavioral goals, not feature checklists.
3. QA Strategy Must Evolve
Normal software QA:
Test Plan:
1. Test all happy paths ✓
2. Test all error paths ✓
3. Test edge cases ✓
4. Automate regression tests ✓
Done.
AI software QA:
Evaluation Plan:
1. Create diverse test prompts (hundreds)
2. Evaluate outputs qualitatively (subjective)
3. Check for hallucinations (manual review)
4. Test adversarial inputs (prompt injection)
5. Measure consistency (same prompt, multiple runs)
6. Gather user feedback (ongoing)
7. Monitor production behavior (continuous)
Never truly "done"—always improving.
Your QA team needs new skills:
- Prompt engineering (to create good test cases)
- Qualitative evaluation (to judge “good” responses)
- Red teaming (to find ways users might break it)
- Behavioral analysis (to spot patterns)
4. User Expectations Require Management
With normal software, users expect:
- ✅ Consistency (same action = same result)
- ✅ Predictability (I know what will happen)
- ✅ Control (I made it do that)
With AI software, users experience:
- ❓ Variability (same question, different answers)
- ❓ Surprise (I didn’t expect that response)
- ❓ Ambiguity (why did it say that?)
PM Impact:
You need to:
- Set expectations in UX: “AI-generated suggestions may vary”
- Provide controls: Regenerate, edit, provide feedback
- Offer transparency: “Based on your preferences…”
- Build trust slowly: Start with low-risk use cases
5. Error Handling Is Completely Different
Normal software errors:
try {
processPayment(amount);
} catch (error) {
if (error.type === 'INSUFFICIENT_FUNDS') {
showError("Insufficient funds. Please add money.");
} else if (error.type === 'INVALID_CARD') {
showError("Invalid card. Please check details.");
}
}
Clear errors. Clear fixes.
AI software “errors”:
User: "Book me a flight to Paris"
AI: "I've booked you a flight to Paris, Texas for next Tuesday."
Is this an error?
- Technically, it answered the question
- But it misunderstood intent
- No error was thrown
- User is now confused or frustrated
How do you catch this?
You can’t with traditional error handling. You need:
- Intent verification (“I found flights to Paris, Texas. Did you mean Paris, France?”)
- Confidence scores (low confidence → ask clarifying questions)
- User feedback loops (“Was this helpful?”)
- Guardrails (if booking flights, always confirm location)
The Hybrid Architecture: How to Actually Build Products
Here’s the reality: Most products won’t be pure normal software or pure AI software.
They’ll be hybrid.
And that’s actually the smartest approach.
The Framework: When to Use What
Use this decision tree for every feature:
Use Normal Software When:
✅ Transactions are involved
- Payments
- Order processing
- Inventory management
- User authentication
✅ Exact accuracy is required
- Financial calculations
- Legal compliance
- Security/access control
- Data integrity
✅ Deterministic logic is sufficient
- Simple if/else decisions
- Database queries
- CRUD operations
- Validation rules
Use AI Software When:
✅ Natural language is involved
- User questions/queries
- Content generation
- Conversational interfaces
- Document analysis
✅ Personalization is needed
- Recommendations
- Dynamic content
- Adaptive UX
- Smart defaults
✅ Pattern recognition helps
- Image analysis
- Sentiment detection
- Anomaly detection
- Trend identification
✅ Creativity adds value
- Writing assistance
- Design suggestions
- Idea generation
- Content summarization
Example Hybrid Architecture
Let’s say you’re building a customer support tool:
User Question (Natural Language)
↓
[AI: Understand Intent]
↓
├─→ Intent: "Check order status"
│ ↓
│ [Normal Software: Query Database]
│ ↓
│ [AI: Format Response Naturally]
│ ↓
│ "Your order #12345 shipped yesterday and will arrive Friday"
│
├─→ Intent: "How do I return an item?"
│ ↓
│ [Normal Software: Retrieve Return Policy]
│ ↓
│ [AI: Explain in User's Context]
│ ↓
│ "To return your shoes, log into your account..."
│
└─→ Intent: "General question about products"
↓
[AI: Generate Helpful Response]
↓
[Normal Software: Log Conversation]
The pattern:
- AI handles understanding and communication
- Normal software handles data and transactions
- AI makes it feel natural
- Normal software keeps it reliable
Real Product Example: Notion AI
Notion is a perfect example of hybrid architecture:
Normal Software Components:
- Database (blocks, pages, workspaces)
- Permissions and access control
- Real-time sync
- Version history
- Collaboration features
AI Software Components:
- “Ask AI” feature (natural language queries)
- Auto-summarization
- Writing assistance
- Content generation
- Smart categorization
Why this works:
- Your data is safe (deterministic storage)
- Your permissions work (rule-based security)
- Your collaboration is predictable (standard sync)
- But your writing gets AI help when needed
- And your content gets smart suggestions
- Plus you can query your data conversationally
They didn’t replace normal software with AI—they augmented it.
The New Developer Skills (And What PMs Need to Know)
If you’re working with engineering teams building AI features, here’s what they need to learn—and what you need to understand:
1. Prompt Engineering
What it is: The art/science of crafting inputs that get desired outputs from AI models.
Example:
❌ Bad prompt:
"Write email"
✅ Good prompt:
"Write a professional email declining a meeting request.
Tone: Polite but firm
Length: 3-4 sentences
Include: Thanks, brief reason, suggest alternative
Do not: Over-apologize or provide excessive detail"
What PMs need to know:
- Prompts are like code—they need testing and iteration
- Small wording changes can dramatically affect output
- Your engineers will spend significant time on prompt refinement
- Budget time for “prompt debugging”
2. Probabilistic Thinking
What it is: Accepting that AI won’t be 100% accurate, and designing for it.
Example scenarios:
Normal Software Thinking:
"This validation will catch 100% of invalid emails"
Probabilistic Thinking:
"This AI will correctly identify spam 95% of the time.
We need fallbacks for the 5%:
- User can report false positives
- Human review for edge cases
- Clear feedback mechanism"
What PMs need to know:
- Plan for imperfection
- Build feedback loops
- Design graceful degradation
- Set realistic expectations with stakeholders
3. Model Evaluation
What it is: Determining if an AI model is “good enough” when there’s no single right answer.
Example evaluation framework:
Test Set: 100 customer support queries
Metrics:
- Relevance: Does response address the question? (90% good)
- Tone: Is response appropriately professional? (95% good)
- Accuracy: Are facts correct? (85% good)
- Helpfulness: Would this satisfy the user? (88% good)
- Safety: No harmful/inappropriate content? (100% good)
Overall: 91.6% "good enough" → Ship it
What PMs need to know:
- You’ll use qualitative metrics (not just pass/fail)
- Evaluation requires human judgment
- You’ll need diverse test cases
- “Good enough” is context-dependent
4. Hybrid Architecture Design
What it is: Knowing when to use deterministic code vs AI, and how to connect them.
Decision framework:
For each feature, ask:
1. Does it need to be 100% accurate?
YES → Normal Software
NO → Maybe AI
2. Does it involve natural language?
YES → Probably AI
NO → Maybe Normal Software
3. Does it handle money/security/compliance?
YES → Normal Software (with possible AI layer)
NO → AI is safer
4. Do users need to understand why it did something?
YES → Normal Software (more explainable)
NO → AI is okay
5. Will outputs vary but still be acceptable?
YES → AI is fine
NO → Normal Software
What PMs need to know:
- Most features will be hybrid
- The boundaries between AI and normal code matter
- Your engineers need to design these interfaces carefully
- Architecture decisions have long-term implications
Practical Frameworks for PMs
Alright, enough theory. Let’s get tactical.
Here are frameworks you can use this week to start managing AI features better:
Framework 1: The AI Feature Spec Template
## Feature: [Name]
### Problem Statement
What user problem does this solve?
### AI Component
What will the AI do?
- Input: What goes into the model?
- Output: What comes out?
- Behavior: How should it act?
### Examples of Good Behavior
[Provide 3-5 examples of ideal inputs and outputs]
Example 1:
Input: "I need help writing a performance review"
Output: "I'd be happy to help. Could you tell me:
- What role is this for?
- What are 2-3 key achievements?
- Any areas for improvement?
This will help me tailor the review appropriately."
### Examples of Bad Behavior
[Provide 3-5 examples of what NOT to do]
Example 1:
Input: "I need help writing a performance review"
Output: "Here's a generic performance review template..."
(Too generic, doesn't gather context)
### Guardrails
What should the AI NOT do?
- Don't generate hateful content
- Don't make up facts about people
- Don't provide legal advice
- Don't promise outcomes we can't deliver
### Normal Software Components
What deterministic code is needed?
- Input validation
- Output formatting
- Error handling
- Logging/monitoring
### Success Metrics
How do we know it's working?
- Quantitative: X% of users click "thumbs up"
- Qualitative: User interviews show positive sentiment
- Business: X% increase in feature completion
### Failure Modes
What could go wrong?
- Hallucination: Model makes up information
- Tone mismatch: Response is too casual/formal
- Misunderstood intent: Model answers wrong question
### Mitigation Strategies
How do we handle failures?
- Regeneration option
- User can edit output
- Feedback mechanism
- Human escalation for complex cases
Framework 2: The AI Testing Checklist
Before shipping any AI feature, run through this:
☐ Diversity Testing
☐ Tested with 50+ varied inputs
☐ Tested edge cases
☐ Tested adversarial inputs (trying to break it)
☐ Tested different user personas
☐ Quality Assessment
☐ Measured relevance (does it answer the question?)
☐ Measured tone (is it appropriate?)
☐ Measured accuracy (are facts correct?)
☐ Measured safety (no harmful content?)
☐ Consistency Check
☐ Same input tested 10 times
☐ Outputs vary but maintain quality
☐ No wild swings in behavior
☐ Failure Mode Testing
☐ What happens with gibberish input?
☐ What happens with malicious input?
☐ What happens with ambiguous input?
☐ Are error states handled gracefully?
☐ User Experience
☐ Loading states clear
☐ Regeneration option provided
☐ Editing capability available
☐ Feedback mechanism present
☐ Monitoring Setup
☐ Logging all inputs/outputs
☐ Tracking user feedback
☐ Monitoring for hallucinations
☐ Alert thresholds configured
Framework 3: The Stakeholder Communication Template
When explaining AI features to non-technical stakeholders:
"Here's what you need to know about our AI feature:
1. It works differently than normal software
- Think of it like hiring a smart assistant vs programming a robot
- The assistant understands context and adapts
- But it might occasionally misunderstand or make mistakes
2. Testing takes longer
- We can't just check "does it work: yes/no"
- We need to evaluate: "does it behave well in most cases?"
- We'll be testing with real users and iterating
3. It won't be perfect at launch
- We're targeting 90-95% good responses
- The remaining 5-10% will improve over time with feedback
- This is normal and expected for AI features
4. Timelines are estimates, not guarantees
- Prompt engineering requires iteration
- We might need to try different approaches
- Buffer: [X weeks] for unforeseen adjustments
5. Success looks like this
- Users engage with the feature (X% usage rate)
- Users give positive feedback (X% thumbs up)
- Business metric improves (X% increase in [metric])
What this means for you:
- Be patient with iteration cycles
- Help us gather user feedback early
- Understand that "done" means "good enough to launch and improve"
Common Mistakes (And How to Avoid Them)
I’ve made every one of these mistakes. Learn from my pain.
Mistake 1: Spec’ing AI Features Like Normal Features
What I did:
Acceptance Criteria:
- When user asks about pricing, show pricing page link
- When user asks about features, list top 3 features
Why it failed: AI doesn’t follow exact rules. It interprets. Sometimes it linked to pricing, sometimes it explained pricing, sometimes it asked clarifying questions. All technically “correct” but inconsistent.
What to do instead:
Behavioral Requirements:
- When user asks about pricing, provide helpful pricing information
- Response should either:
a) Direct them to pricing page if they want details
b) Summarize key pricing tiers if they want overview
c) Ask clarifying questions if intent is unclear
Examples: [provide 5-10 examples of good responses]
Mistake 2: Expecting Exact Timelines
What I did: “This AI feature should take 2 weeks, same as our last feature.”
Why it failed: Prompt engineering took 3 weeks. We had to iterate on model behavior. “Done” was subjective. We missed the deadline by 4 weeks.
What to do instead:
- Add 50-100% buffer to initial estimates
- Break into phases: MVP → Iteration → Polish
- Set behavioral goals, not completion dates
- Plan for feedback loops
Mistake 3: Launching Without Feedback Mechanisms
What I did: Shipped AI feature. Users complained. We had no way to know what was wrong or how often.
Why it failed: We couldn’t improve because we didn’t know what to fix.
What to do instead:
- Always include thumbs up/down
- Log every interaction (input + output)
- Add “Report issue” option
- Monitor user feedback channels
- Review logs weekly
Mistake 4: Treating Hallucinations Like Bugs
What I did: AI made up a fact. I filed a bug ticket. Engineers said “that’s not a bug, that’s how AI works.”
Why it failed: You can’t “fix” hallucinations like you fix code bugs. They’re emergent behaviors. You mitigate them through better prompts, guardrails, and verification.
What to do instead:
- Design for verification (show sources, add confidence scores)
- Implement fact-checking layers for critical information
- Add human-in-the-loop for high-stakes decisions
- Set clear expectations with users (“AI-generated, verify important details”)
Mistake 5: Not Budgeting for Compute Costs
What I did: Estimated infrastructure costs based on our normal software. Launched AI feature. AWS bill was 10x higher than expected.
Why it failed: GPU compute is expensive. Every AI request costs significantly more than a normal API call.
What to do instead:
- Get cost estimates per 1000 requests BEFORE building
- Implement caching where possible
- Add rate limiting
- Consider smaller models for simple tasks
- Monitor costs daily during beta
Mistake 6: Assuming QA Knows How to Test AI
What I did: Gave QA team the AI feature. They tested it like normal software. Missed major issues.
Why it failed: QA was checking “does it work?” not “does it behave appropriately?” They didn’t know to test for:
- Hallucinations
- Prompt injection attacks
- Tone consistency
- Edge cases in natural language
What to do instead:
- Train QA on AI-specific testing
- Create diverse test prompts (100+)
- Include adversarial testing
- Do qualitative evaluation sessions
- Involve actual users in beta testing
The Future: What’s Coming Next
We’re still early. Here’s what I’m watching:
1. Multi-Modal Models
Current: Text in → Text out
Coming: Any input → Any output
- Voice + image + text → Video + audio + text
- “Show me beach vacation options” → Interactive video with voiceover
PM Impact: Features will get even more complex. You’ll need to think across modalities.
2. Agents (AI That Takes Actions)
Current: AI generates responses
Coming: AI takes actions on your behalf
- “Book me a flight to Paris” → AI actually books it
- “Fix the bug in checkout flow” → AI writes and deploys the fix
PM Impact: You’re no longer shipping features—you’re shipping autonomous capabilities. Liability, safety, and control become critical.
3. Reasoning Models
Current: Models generate, don’t really “think”
Coming: Models that show their reasoning process
- “Why did you recommend this?” → Clear step-by-step logic
- More explainable decisions
- Better alignment with human intent
PM Impact: Trust will increase. Users will better understand AI behavior. Your features become more debuggable.
4. Smaller, Specialized Models
Current: One big model tries to do everything
Coming: Lots of small models, each excellent at one thing
- One model for summarization
- Another for sentiment
- Another for classification
PM Impact: More architectural decisions. You’ll compose multiple models. Like microservices, but for AI.
5. Real-Time Learning
Current: Models are static after training
Coming: Models that learn from user interactions in real-time
- Your writing assistant gets better the more you use it
- Your search understands your preferences without explicit settings
PM Impact: Personalization reaches new levels. Privacy concerns intensify. You’ll need clear data policies.
Key Takeaways: What Every PM/Founder Needs to Remember
Let me distill everything into the essentials:
1. Architecture Is Fundamentally Different
Normal software: Deterministic, rule-based, predictable
AI software: Probabilistic, learned, adaptive
Stop using the same playbook for both.
2. Specification Style Must Change
Normal software: “When user does X, system does Y”
AI software: “When user does X, system should behave like Y (with examples)”
You’re specifying behaviors, not outputs.
3. Testing Requires New Approaches
Normal software: Pass/fail unit tests
AI software: Qualitative evaluation of behaviors
Your QA team needs new skills.
4. Timelines Are Estimates, Not Commitments
Normal software: Predictable sprints
AI software: Iterative refinement with fuzzy completion
Build in buffer. Embrace iteration.
5. Most Products Will Be Hybrid
Don’t go all-in on AI. Don’t avoid it entirely.
Use normal software where you need reliability.
Use AI where you need intelligence.
Design the boundaries carefully.
6. Failure Modes Are Different
Normal software: Crashes, errors, bugs
AI software: Hallucinations, misunderstandings, inappropriate responses
Design for graceful degradation and user feedback.
7. Costs Are Higher (Initially)
Normal software: CPU compute
AI software: GPU compute (10-100x more expensive)
Budget accordingly. Optimize aggressively.
8. The Skills Gap Is Real
Your team knows normal software.
They’re learning AI software.
Invest in training. Hire people who bridge both worlds. Be patient with the learning curve.
Your Action Plan: What to Do This Week
Don’t just read this and forget it. Here’s what to do immediately:
Monday: Audit Your Current Features
Go through your product roadmap and mark each feature:
- 🔵 Normal Software (deterministic)
- 🟢 AI Software (probabilistic)
- 🟡 Hybrid (mix of both)
For any 🟢 or 🟡 features, ask:
- Are we spec’ing this correctly?
- Does our team know how to build this?
- Do we have the right testing approach?
- Have we budgeted for infrastructure costs?
Tuesday: Update Your Templates
- Revise your user story template for AI features
- Create the AI testing checklist
- Draft the stakeholder communication template
- Share with your team
Wednesday: Have the Architecture Conversation
Sit down with your engineering lead. Ask:
- “Which of our features are deterministic vs probabilistic?”
- “Where are we using AI when normal software would be better?”
- “Where could AI add value but we’re using rigid code?”
- “What architectural decisions do we need to revisit?”
Thursday: Train Your Team
- Share this article with PMs, engineers, QA
- Host a 1-hour discussion
- Identify knowledge gaps
- Plan training sessions
Friday: Adjust Your Roadmap
Based on what you’ve learned:
- Add buffer to AI feature timelines
- Build in feedback mechanisms
- Plan for iteration cycles
- Set realistic expectations with stakeholders
Final Thoughts: We’re All Learning
Here’s the truth: Nobody has this figured out yet.
Not the big tech companies. Not the AI startups. Not the consultants selling you “AI strategy.”
We’re all learning in real-time.
The difference between teams that succeed and teams that struggle isn’t expertise—it’s recognizing that the rules changed and adapting accordingly.
You don’t need to be an AI expert.
You don’t need a PhD in machine learning.
You don’t need to understand transformer architecture in detail.
You just need to understand that AI software is different, and build accordingly.
- Spec for behaviors, not outputs
- Test for quality, not correctness
- Embrace iteration, not perfection
- Design hybrid systems, not all-or-nothing
- Build feedback loops, not fire-and-forget features
The teams that do this will build the next generation of products.
The teams that don’t will keep wondering why their AI features feel broken, even when the code “works.”
What’s Next?
This is just the beginning of the conversation.
Coming soon on The Naked PM:
- How to write effective AI feature specs (with templates)
- The QA playbook for AI features
- Pricing and cost optimization for AI products
- Prompt engineering for product managers
- Building trust in probabilistic systems
Want to go deeper?
I’m creating a complete AI Product Management toolkit:
- Spec templates
- Testing frameworks
- Stakeholder communication guides
- Real product examples
- Lessons from the trenches
Download the free AI PM Starter Kit (includes all the frameworks from this post, plus bonus templates)
Let’s Keep the Conversation Going
I’d love to hear from you:
- What AI features are you building?
- What challenges are you facing?
- What mistakes have you made (so we can all learn)?
- What’s working well for your team?
Comment below or reach out:
- LinkedIn: [https://www.linkedin.com/in/karthicksivaraj/]
- Twitter/X: [https://x.com/TheNakedPM_]
- Email: (mailto:hello@nakedpm.com)
Found this helpful? Share it with:
- PMs struggling with AI features
- Engineers building AI products
- Founders trying to figure out AI strategy
- Anyone who thinks AI is “just another feature”
Resources & Further Reading
For deeper technical understanding:
- The Illustrated Transformer - Jay Alammar
- Attention Is All You Need - The original Transformer paper
- State of GPT - Andrej Karpathy
For product management:
- AI Product Management - O’Reilly
- Building LLM Applications - O’Reilly
For keeping up with the space:
- The Batch - Andrew Ng’s AI newsletter
- Import AI - Jack Clark’s weekly AI newsletter
- r/MachineLearning - Reddit community
This post was written by a human product manager (me), refined with help from AI tools, and based on real experiences building AI features in production. The irony is not lost on me.
About The Naked PM
We cut through the BS and give product managers the tactical, honest insights they need to build better products. No fluff. No jargon. Just real talk from the trenches.
Subscribe for weekly posts on product management, AI, engineering collaboration, and the messy reality of building software in 2025.