
Table of Contents
- The $47K Lesson: Why This Guide Exists
- Why Understanding This Actually Matters
- The 5-Phase Journey (It’s Not Just “Deploy”)
- Phase 1: Planning - Where Most Disasters Start
- Phase 2: Development - What “Code is Done” Actually Means
- Quick Check-In: Where We Are
- Phase 3: Build & Package - The Automated Safety Net
- Phase 4: Testing & Validation - Before Users See It
- Phase 5: Deployment - Going Live
- Deployment Strategies: Which One Actually Works For You
- Build Failure Troubleshooting Guide
- Deployment Disasters I’ve Witnessed
- When Things Go Wrong: Incident Response
- Real Timelines: Stop Guessing, Start Planning
- Your Role as PM in This Entire Process
- PM’s Incident Response Playbook
- Questions to Ask During Sprint Planning
- Measuring Success: These Are the Metrics That Matter
- Your Action Plan: Start This Week
- Final Thoughts
The $47K Lesson: Why This Guide Exists
Two years ago, I made a mistake that cost our company $47,000 in one weekend.
I wanted to update our pricing page. Just change some numbers, update tier descriptions. Simple, right? My engineering team said it would take a week. I pushed back: “It’s just text changes, why so long?”
They relented. We rushed it. I asked for a Friday afternoon deployment because I wanted to announce it Monday morning.
Here’s what I didn’t understand: The pricing page wasn’t “just text.” It connected to our payment system. Changes required database migrations. We hadn’t tested in staging. Our rollback plan was “hope nothing breaks.”
Friday 4:45pm: Code deployed
Friday 5:15pm: I went home, proud
Friday 6:00pm: Checkout broke for all users
Friday 7:30pm: Support tickets flooding in
Saturday 2am: Finally rolled back after 12+ hour emergency shifts
Damage: $47K in lost sales, 3 engineers working overnight, 150 angry customers, and my credibility with engineering destroyed.
The worst part? Entirely preventable.
That weekend, I made a decision: I’d never again let a feature ship without understanding the full journey from code to production. That decision—and what I learned—is what this guide is about.
Why Understanding This Actually Matters
You might be thinking: “I manage the product vision. Why do I need to understand deployment pipelines?”
Fair question. Here’s why it matters:
You set better timelines. When engineering says “2 weeks,” you stop asking “why so long?” because you understand that 2 weeks includes planning, development, testing, staging, and deployment. Not just “writing code.”
You spot bottlenecks early. When someone says “builds are slow” or “we’re blocked on CI/CD,” you recognize this doesn’t just affect one feature—it affects your entire team’s ability to ship.
You make smarter trade-off decisions. You know which shortcuts are dangerous (skip testing) vs. acceptable (reduce scope). You protect your team from avoidable disasters.
Engineering respects you more. When you ask “what’s our rollback plan?” instead of “why isn’t this done yet?”, engineers realize you understand the stakes.
Your team ships faster. This is backed by data. Teams with PMs who understand the deployment process ship 2-3x more features per quarter. Not because they work harder—because they work smarter.
💡 The Real Secret: You don’t need to know HOW to set up a CI/CD pipeline. You need to know WHAT it does and WHEN it becomes a blocker. That’s the difference between a tactical PM and a strategic one.
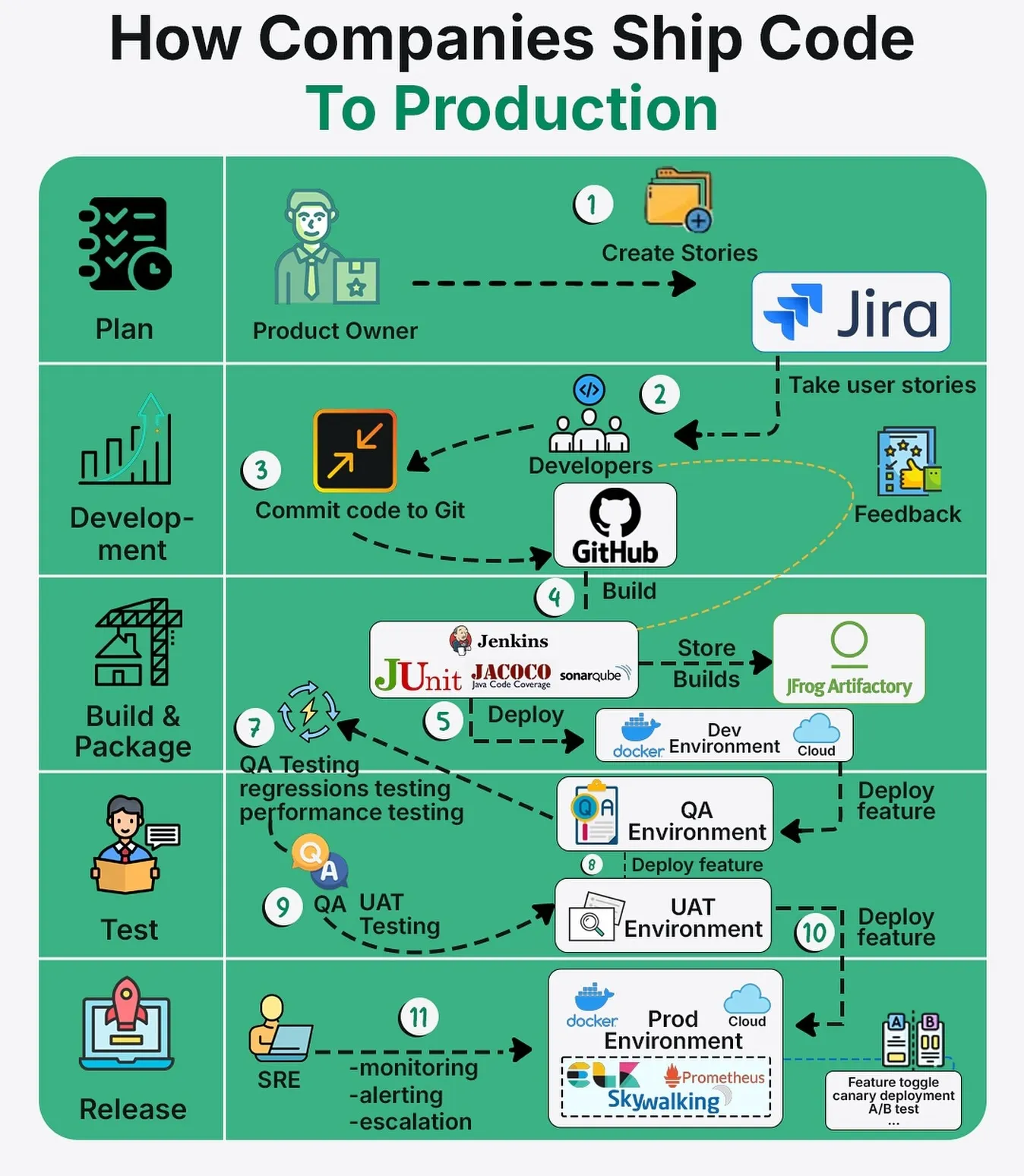
The 5-Phase Journey (It’s Not Just “Deploy”)
Every feature you ship goes through five distinct phases. Here’s the problem: most PMs only see phase 1 and phase 5. The disasters happen in 2, 3, and 4.
Here’s the complete flow:
┌──────────────┐
│ PLANNING │ ← You lead this (5-7 days)
│ │ Define WHAT we're building
└──────┬───────┘
↓
┌──────────────┐
│ DEVELOPMENT │ ← Engineering writes code (5-10 days)
│ │ "Code is done" ≠ "Feature shipped"
└──────┬───────┘
↓
┌──────────────┐
│ BUILD & │ ← Automated checks (15-30 min)
│ PACKAGE │ Discovery phase for issues
└──────┬───────┘
↓
┌──────────────┐
│ TESTING │ ← QA + PM validate (3-7 days)
│ & STAGING │ Real environment testing
└──────┬───────┘
↓
┌──────────────┐
│ DEPLOYMENT │ ← Safe rollout to production (1-14 days)
│ │ Monitoring and incident response
└──────────────┘
Total Timeline: 4-6 weeks (normal teams)
Elite Teams: 10-14 days
Key insight: Each phase catches different problems. Skip one, something breaks.
Phase 1: Planning - Where Most Disasters Start
Here’s an uncomfortable truth: most deployment disasters begin in planning, not deployment.
Vague requirements → Engineers make assumptions → Wrong assumptions discovered during testing → Everything delays → You rush deployment → Production breaks.
I’ve seen this cycle dozens of times.
The Requirements Problem
I once saw a PM write:
“User Story: Add social login
Acceptance Criteria: Users can log in with social accounts”
That’s it. No details. No edge cases. Just “add social login.”
Here’s what engineering had to ask:
“Which providers? Google? Apple? Facebook? Existing users linking accounts? Mobile apps or web? What about GDPR compliance? What happens if the social provider is down? What if email already exists in our system?”
Every single question should have been answered upfront.
Good Requirements Save Weeks
Compare that to how this SHOULD have been written:
User Story:
As a mobile app user, I want to log in with Google or Apple ID
So I can access my account in <10 seconds without remembering passwords
Context:
- 43% of users abandon signup due to password friction
- Competitors offer social login
- Support gets 50 password reset tickets per week
Acceptance Criteria:
Functional:
☐ New users can sign up with Google or Apple ID
☐ Existing users can link social to email account
☐ Login completes in <3 seconds
☐ Works on iOS and Android native apps
☐ Graceful fallback to email if social login fails
Edge Cases:
- User denies social permissions → Show message, offer email option
- Social provider down → Automatic fallback
- Email already exists → Prompt to link accounts
- User logs in with Google, then tries Apple → Link accounts or prompt
Success Metrics (Track 30 days):
- 40% of new signups use social login
- Login abandonment drops from 28% to <15%
- Password reset tickets drop by 30%
Out of Scope V1:
- Twitter/LinkedIn login (V2)
- Auto-switching between accounts (V2)
This takes an extra 2 hours to write. But here’s the impact:
- Development time: Reduced 35% (no daily clarifying questions)
- Testing cycles: Reduced 40% (fewer surprises)
- Production bugs: Reduced 60% (everyone knows what “done” means)
Translation: 2 hours of upfront work saves 10+ days in development and testing.
Your Planning Checklist
Before a feature moves to development, answer ALL of these:
☐ What problem does this solve? (with actual data)
☐ What does success look like? (specific, measurable)
☐ What are ALL the edge cases?
☐ What happens when things go wrong?
☐ What are the technical constraints?
☐ What's explicitly OUT of scope for V1?
☐ Have engineering/design/QA reviewed this together?
If you can't check all boxes → Story isn't ready
Send it back → Discover issues cheaply, not expensively
Phase 2: Development - What “Code is Done” Actually Means
Here’s where communication breaks down:
You ask: “Is the feature done?”
Engineer says: “Yes, code is done.”
You think: “Great! Let’s ship it!”
They think: “Code is written. Still needs review, testing, validation, and deployment.”
This gap in language creates 90% of “Why isn’t this live yet?” frustration.
The Real Development Timeline
Here’s what actually happens, day by day:
Days 1-2: Engineer creates feature branch
Writes code incrementally
Tests locally
Commits small changes
Days 3-5: Core functionality working
Adds error handling for edge cases
Writes automated tests (critical)
Adds logging and monitoring
Day 6: Opens Pull Request (PR) for review
Automated checks run:
• Code quality scan (2 min)
• Security scan (3 min)
• Unit tests (5 min)
• Build verification (3 min)
If ANY fail → Engineer fixes, waits for re-check
Day 7: Code Review (peer review)
1-2 teammates read code for:
• Logic errors
• Security issues
• Performance problems
• Code maintainability
Feedback given. Engineer addresses.
Reviewer approves.
Day 8: Merge to main branch
Build pipeline starts automatically
Code is now part of next release candidate
Total typical timeline: 8 days
When Timelines Explode
The bottleneck is usually code review. You see “Waiting for review” for 3 days and wonder why. Here’s what’s actually happening:
- Reviewers have their own work and deadlines
- A proper code review takes 30-60 minutes of focused thinking
- They find issues. Engineer fixes. Needs re-review.
- Sometimes 2-3 review cycles happen before approval
Your leverage as PM: In sprint planning, ask “Who’s assigned to review this work? Do they have capacity?”
🎯 Real Story: The Mid-Sprint Scope Explosion
During a sprint, we were building a search feature. On Day 4, the PM watched a demo and had an idea:
PM: “Can we add date and category filters too?”
Engineer: “That wasn’t in the original scope…”
PM: “But we’re already building search. It’s just two more filters!”
Here’s what actually happens when you add filters mid-sprint:
Original estimate: 5 days Add filters implementation: +3 days Tests for filter combinations: +1.5 days Edge cases discovered during testing: +1 day Risk factor from rushed work: High
New timeline: 10.5 days (that’s 210% increase for “just two filters”)
What should have happened:
PM: "Valuable insight. V2 or extend V1?"
Eng: "Now: +5 days, risky. V2: 4 days, clean."
PM: "Ship V1 on schedule. Filters in V2 next sprint."
Result: Hit deadline, better quality, happy team
⚠️ Critical Rule: Mid-sprint scope changes are a siren song. They sound good in the moment. They destroy sprint plans. Save them for V2.
Quick Check-In: Where We Are
We’ve covered the foundation:
✓ Planning - Where problems start
✓ Development - What “code is done” means
✓ Building - Coming next
At this point, your feature is written, reviewed, and ready to be built. But here’s what’s critical to understand: the real safety net hasn’t kicked in yet.
Next, we go deeper into the automated systems that catch problems before production.
Phase 3: Build & Package - The Automated Safety Net
After your code merges to the main branch, something remarkable happens: an automated system takes over completely.
Think of it like airport security. Your code goes through multiple checkpoints. If it fails ANY checkpoint, it stops immediately.
Here’s what happens in those 15-30 minutes:
The Build Pipeline Breakdown
STEP 1: Code Compilation (2-5 min)
Transform your code into executable application
✓ Compiles successfully → Continue
✗ Compilation errors → Stop and notify engineer
STEP 2: Automated Tests (5-15 min)
Run 1,000+ unit tests simultaneously
Run integration tests
✓ 100% pass → Continue
✗ Any fail → Stop immediately
STEP 3: Code Quality Check (2-5 min)
Analyze code coverage
Scan for code smells/potential issues
✓ Meets standards (80%+ coverage) → Continue
✗ Below threshold → Stop
STEP 4: Security Scan (1-3 min)
Check for known vulnerabilities
Verify no secrets (passwords, API keys) exposed
✓ Secure → Continue
✗ Vulnerabilities found → Stop
STEP 5: Create Deployable Package (1-3 min)
Build Docker image or compiled binary
Tag with version number
Store in secure registry
Package ready for deployment
RESULT:
✓ All checks passed → Feature can deploy to staging
✗ Any check failed → Feature CANNOT ship until fixed
This is intentional. Better to fail in a 10-minute build than in production where customers see it.
Why Builds Fail (And What It Means For You)
1. Tests Failed (Most Common)
What it means: New code broke existing functionality
Example: Added a field to user profiles. Code that reads profiles now crashes because it doesn’t expect the new field.
Fix time: 1-4 hours
Your response: “Thanks for catching this early. What’s the ETA on the fix?”
2. Code Quality Below Standards
What it means: Code coverage dropped or too many potential bugs detected
Example: Engineer wrote 200 lines of code but only 50 lines of tests. Code coverage dropped from 85% to 65%.
Fix time: 2-8 hours to add proper test coverage
Your response: “Is this one-time or a pattern? Do we need to change how we approach testing?”
3. Security Vulnerability Detected
What it means: A library or dependency has a known security flaw
Example: Using an older version of a library. Security researcher just published an exploit.
Fix time: 30 minutes (update the library) to 2 days (if incompatible with existing code)
Your response: “How critical is this? Can customers be compromised? Should we deprioritize this feature?”
4. Build Configuration Issues
What it means: The build system itself is broken
Example: Build server ran out of memory. Docker configuration is wrong.
Fix time: 30 minutes to 2 hours
Your response: “Is this blocking other work too? Should we make this top priority?”
The Hidden Productivity Metric Nobody Talks About
Build time = how long from code merge to deployable package ready
Fast builds: <10 minutes → Ship 10+ times per day
Decent builds: 10-20 min → Ship 3-5 times per day
Slow builds: 20-45 min → Ship 1-2 times per day
Broken builds: 45+ min → Shipping becomes painful
Here’s why this matters: If builds take 45 minutes, engineers can only do ~10 builds per day max. If builds take 10 minutes, they can do 40+ per day. That’s 4x more iteration speed.
Cost analysis of slow builds:
- 5 engineers on team
- Each waits 30 min/day for builds
- 2.5 hours wasted daily = 12.5 hours weekly
- At $100/hour salary cost = $1,250 per week = $65,000 per year
Investing 2 weeks to optimize builds saves $65K annually and makes engineers happier.
💡 PM Leadership Move: If you hear “waiting for build to finish” multiple times per day, that’s developer time literally wasted. Advocate for faster builds. Show the ROI to leadership. This moves the needle.
Phase 4: Testing & Validation - Before Users See It
Your build passed. Great. But “passed automated tests” doesn’t mean “ready for customers.”
That’s where testing in staging comes in.
The Testing Pyramid (Why It Actually Matters)
Not all tests are equal. This pyramid shows how many of each type you need:
/\
/ \ E2E Tests (5%)
/----\ Real user journeys (slow, expensive)
/ \
/Integration\ Integration Tests (15%)
/ Testing \ Component interaction (moderate speed)
/──────────────\
/ Unit Tests \ (80%)
/ ──────────────── \ Individual functions (fast, cheap)
Unit Tests (80%): Test individual functions in isolation. Fast—thousands run in seconds.
test('calculateDiscount applies 10% for premium users', () => {
const result = calculateDiscount(100, 'premium');
expect(result).toBe(90);
});
Why: Cheap to run, catch basic bugs immediately
Integration Tests (15%): Test how different pieces work together. Slower because they use real databases.
Example: “When user creates an order, does it correctly update inventory AND send confirmation email?”
Why: Catch interaction issues that unit tests miss
End-to-End Tests (5%): Simulate real users doing real tasks. Slowest but most realistic.
Example: Real browser opening app, creating account, making purchase
Why: Catch edge cases, real user workflows
Why This Pyramid Shape Matters
- Only unit tests: Miss integration issues (your most expensive bugs)
- Only E2E tests: Too slow. A single E2E test takes 30+ seconds. With 100 tests, that’s 50 minutes per build.
- Proper pyramid: Thorough testing without excessive slowness
What “Staging” Actually Is
Staging is a production-like environment where:
- Code is deployed exactly as it will be in production
- Uses realistic data (not real customer data, but realistic volumes and types)
- Infrastructure matches production (same servers, same databases)
- Safe to test without affecting customers
- You can practice incident recovery and rollbacks
What Gets Tested in Staging
Your QA team systematically tests:
✓ Functional testing: Does the feature work as designed?
✓ Performance testing: Is the system fast enough with realistic data?
✓ Integration testing: Do all components work together?
✓ Data migration testing: Do database changes work correctly?
✓ Rollback testing: Can we undo this deployment if needed?
✓ User acceptance testing: Does this meet requirements?
Issues found in staging are fixed. Code returns to development, fix is tested, comes back to staging. This cycle repeats.
The Timeline Reality
Staging testing typically takes:
- Small feature: 1 day
- Medium feature: 3-5 days
- Large feature: 1-2 weeks
Budget this time. Skipping or rushing staging means problems hit production instead, costing infinitely more.
Phase 5: Deployment - Going Live
Your code has been reviewed, tested thoroughly, validated in staging. Now it goes to production.
Pre-Deployment Verification
Before deploying, verify:
☐ All staging tests passed
☐ Database migrations tested and reversible
☐ Monitoring dashboards configured
☐ Rollback plan documented and tested
☐ Team available for post-deployment monitoring (next 4 hours minimum)
☐ Incident response team on standby
☐ Communication plan in place
☐ Feature flags configured (if using them)
Missing ANY? Don't deploy yet.
Deployment Windows Matter More Than You Think
Good deployment time: Tuesday-Thursday mornings
Why: Team is alert, support available, incident response possible
Risky deployment time: Friday afternoon
Why: Support team going offline, issues happen when no one can help
Never deploy: Holidays, overnight, when team on vacation
Your timing decision directly impacts how fast you recover from incidents. A 4:45pm Friday deployment that breaks at 6pm becomes a 12+ hour incident. A 9am Tuesday deployment that breaks at 9:15am is fixed by 9:30am.
PS. GeeksforGeeks.org
Deployment Strategies: Which One Actually Works For You
Here’s the question I hear constantly: “What deployment strategy should we use?”
The answer: It depends entirely on how much you’re willing to risk.
Let me show you with real scenarios.
Scenario 1: Fixing a Typo in the Footer
Risk level: Zero
Users affected: Technically everyone, realistically nobody
Strategy I’d use: Big Bang deployment
Why: Not worth any complexity. Just ship it to everyone instantly.
Scenario 2: Adding a New Dashboard Widget
Risk level: Low
Users affected: Only users who visit that dashboard
Strategy I’d use: Rolling deployment
Why: Safe enough. Gradually roll out across servers. If something breaks, rollback is straightforward.
Scenario 3: Updating the Pricing Page (Learn From My Mistakes)
Risk level: HIGH
Users affected: Every single customer trying to buy something
Strategy I’d use: Canary deployment
Why: Can’t afford another $47K disaster. This is what saved companies millions.
How it works:
- Deploy to 5% of traffic (30 minutes)
- Monitor error rates and payment success closely
- If everything looks good → Expand to 25% (1 hour)
- If still good → Expand to 50% (1 hour)
- If still good → Expand to 100%
- If anything spikes → Instant rollback to 0%
Scenario 4: Complete Database Migration
Risk level: CRITICAL
Users affected: Entire system goes down if this breaks
Strategy I’d use: Blue-Green deployment
Why: Need instant rollback capability if something catastrophic happens.
How it works:
- Run two identical production environments side by side (Blue and Green)
- Old system handles all traffic (Blue)
- Deploy to Green and run tests with real production traffic
- If everything works → Switch all traffic to Green instantly
- Old system stays running for 24 hours as backup (can switch back instantly)
Cost? Yes, double infrastructure. But data loss costs infinitely more.
Your Decision Framework
Ask yourself these three questions:
Question 1: If this breaks, how many users get affected?
- All users → Canary or Blue-Green (must be safe)
- Some users → Rolling (moderate safety)
- Few users → Big Bang (minimal risk)
Question 2: How fast can we rollback if something breaks?
- <5 minutes → Any strategy works
30 minutes → Must use Blue-Green for critical features
Question 3: What’s the business impact if this fails?
- Revenue loss → Canary or Blue-Green (careful)
- User inconvenience → Rolling (moderate)
- Barely noticeable → Big Bang (fast)
When in doubt: Ask your engineering lead: “What deployment strategy would you use for this? What could go wrong?”
They’ll respect that you’re asking the right questions.
📧 The Build Failure Troubleshooting Guide
Is your build pipeline breaking frequently?
Learn what each build failure actually means and how to respond as a PM.
Includes:
- Quick reference guide: “Build failed because…”
- What questions to ask engineering
- How to prioritize fixes
- How to prevent future failures
Deployment Disasters I’ve Witnessed (So You Don’t Have To)
Disaster 1: The Friday 4pm “Quick Fix”
What happened: PM pushed for Friday afternoon deployment of “quick bug fix”
What went wrong: The “quick fix” broke user authentication
Result: No one could log in for 8 hours (overnight while everyone was offline)
Business impact: $23K in lost sales, 200 angry support tickets
Lesson learned: No such thing as a “quick” production deployment. Timing matters more than speed.
Disaster 2: The Database Migration That Seemed Simple
What happened: “Just adding one field to users table, should be instant”
What went wrong: Migration took 4 hours on production database (had 50 million users)
Result: Site down during peak traffic, customers couldn’t use product
Business impact: $35K in lost revenue, damaged customer trust
Lesson learned: Test migrations with production-sized data. Always.
Disaster 3: The “We Don’t Need Staging” Sprint
What happened: To “save time,” team shipped directly to production
What went wrong: Feature broke core checkout workflow
Result: 2,000 users hit the broken feature before anyone noticed
Business impact: $47K lost (yes, this is my story)
Lesson learned: Staging isn’t bureaucracy. It’s insurance.
Each of these cost tens of thousands. Your job as PM: prevent them by asking the right questions upfront.
When Things Go Wrong: Incident Response
Problems happen to every team. What separates great teams from struggling teams is how fast you respond.
How Issues Get Caught (Before Customers Notice)
With proper monitoring, your systems catch problems within minutes.
Example incident timeline:
8:14pm: Deployment complete, monitoring starts
8:47pm: Error rate spikes to 3% (automated alert fires)
8:49pm: On-call engineer gets paged
8:51pm: Engineer investigating (checks logs, traces errors)
9:03pm: Root cause identified
9:07pm: Decision: Rollback or fix forward?
9:08pm: Rollback initiated
9:12pm: Service restored, customers back online
9:30pm: Team notification and status update
Total outage time: 18 minutes
Without monitoring? Customer calls support at 9:47pm. Support realizes there’s an issue. Takes 30 minutes to escalate to engineering. It’s 10:17pm. Engineers on call now, but not at full focus. Incident lasts 6+ hours.
Rollback vs. Fix-Forward: The Decision Framework
When something breaks, you must decide quickly:
Rollback (revert to previous version) when:
- Issue is critical (payment failures, data loss, security breach)
- Root cause is unknown
- Fix will take more than 30 minutes
- You want to be safe
Fix-Forward (deploy a fix on top) when:
- Issue is minor
- Root cause is obvious and simple
- Fix is quick (5-10 minutes)
- Rollback would cause other problems
Good teams can rollback in under 5 minutes. This is why they deploy confidently.
Post-Incident: Blameless Learning
After every incident, your team should review:
1. What happened?
2. What was the impact? (customers affected, revenue lost, duration)
3. What did we do to recover? (rollback, fix, etc.)
4. What could we have done to prevent this?
5. What's our action plan to prevent recurrence?
Critical: No blame. Focus on system improvements.
📧 The Deployment Strategy Decision Tree
Not sure which deployment strategy to use?
Interactive flowchart: Answer 3 questions, get your deployment strategy.
Includes:
- Decision tree for every feature type
- When to use Big Bang, Rolling, Canary, Blue-Green
- Real scenarios and examples
- Common mistakes to avoid
Real Timelines: Stop Guessing, Start Planning
📊 The PM’s Sprint Estimation Calculator
Stop guessing at timelines. Answer 5 questions about your feature, get realistic estimates based on industry data.
Includes:
- Small/Medium/Large feature templates
- Risk factor adjustments
- Team velocity multipliers
- Built-in buffer recommendations
Let me give you actual numbers for actual features so you can plan realistic releases.
Small Feature (UI/UX Change, No Backend)
Example: Button color change, text update, layout adjustment
Planning: 1-2 days
Development: 2-3 days
Build: 15 min
Testing: 1 day
Deployment: 2 hours (Big Bang)
─────────────────────────
Total: 4-6 days (1 sprint)
Medium Feature (New Functionality)
Example: Social login, PDF export, dashboard widget
Planning: 3-5 days
Development: 7-10 days
Build: 20-30 min
Testing: 3-5 days
Deployment: 1-3 days (Rolling or Canary)
─────────────────────────
Total: 14-23 days (3-4 weeks)
Large Feature (New Product Area)
Example: New checkout flow, admin dashboard, payment system
Planning: 1-2 weeks
Development: 3-4 weeks
Build: 30 min
Testing: 1-2 weeks
Deployment: 2-4 weeks (Blue-Green, careful rollout)
─────────────────────────
Total: 7-12 weeks (2-3 months)
Average vs. Elite Teams (Same Feature, Different Execution)
Average Team Timeline:
Planning: 5 days (vague requirements)
Development: 10 days (daily clarifying questions)
Build: 45 min (slow, breaks often)
Testing: 5 days (mostly manual)
Deployment: 3 days (risky, manual)
─────────────────────────
Total: 23 days (4.6 weeks)
Elite Team Timeline:
Planning: 3 days (clear requirements)
Development: 5 days (no blockers)
Build: 10 min (fast, reliable)
Testing: 2 days (mostly automated)
Deployment: 1 day (automated, safe)
─────────────────────────
Total: 11 days (2.2 weeks)
Difference: 2.1x faster shipping
What’s the difference? Elite teams don’t work harder. They work smarter:
✓ Clear requirements save 40% dev time
✓ Fast builds save 2-3 hours daily
✓ Automated testing saves 60% QA time
✓ Safe deployment reduces incidents
💡 The Lesson: Speed comes from process maturity, not heroic effort. Same engineers, better system = double the shipping velocity.
Your Role as PM in This Entire Process
You don’t deploy code. But you play three critical roles that determine whether deployments succeed or fail.
Role 1: Advocate for Proper Process
Sometimes teams want to skip steps to “save time.” Recognize this as a trap.
❌ Bad PM move: “Just ship it, we’ll fix issues later”
✅ PM Leadership: “What would proper testing reveal? Let’s take the time now.”
Proper process saves time long-term. One production incident costs more than a dozen slow sprints.
Role 2: Plan Realistic Timelines
Understand deployment duration so you set realistic deadlines and stop surprising your team.
❌ Unrealistic: “Can you ship the new checkout by Wednesday? It’s just a form redesign.”
✅ Realistic: “New checkout takes 4-6 weeks because it touches payments. Here’s the timeline: Planning (1 week), Development (2 weeks), Testing & Staging (1 week), Deployment (1 week). That puts us at month-end.”
Accounting for testing, validation, and safe deployment prevents everyone from frustrated “we missed the deadline!”
Role 3: Make Smart Risk Decisions
You decide acceptable risk level. This is a joint decision with engineering, but the business call is yours.
Example conversation:
PM: "How risky is this payment system change?"
Eng: "It's critical infrastructure. Payment failures = revenue loss."
PM: "Okay. Let's use canary deployment. 5% for 2 hours,
monitor closely, then expand. If any errors spike, rollback."
Eng: "Good call. That gives us the safety margin we need."
You’re not making technical decisions. You’re making business risk decisions based on engineering input.
📧 The PM’s Incident Response Playbook
When production breaks (and it will), do you know what to do?
Step-by-step playbook for handling incidents:
Includes:
- The first 5 minutes: What to do immediately
- Communication templates: What to tell customers, leadership, team
- Decision framework: Rollback or fix forward
- Post-incident review template
- How to prevent similar incidents
Questions to Ask During Sprint Planning
Sprint Planning Checklist (Screenshot This)
About Timeline: ☐ How long does code need in staging? ☐ When’s a safe deployment window? ☐ How long does rollback take if something breaks? ☐ Any dependencies on other features?
About Risk: ☐ What could go wrong with this deployment? ☐ Does this have breaking changes? ☐ How do we limit impact if something breaks? ☐ What deployment strategy is safest?
About Monitoring: ☐ What metrics should we watch post-deployment? ☐ What indicates success? What indicates failure? ☐ Are we monitoring the right things?
About Communication: ☐ Who needs notification before deployment? ☐ What’s our incident response plan?
Print this. Bring to every planning meeting.
These questions show you understand the stakes.
Measuring Success: These Are the Metrics That Matter
How do you know if your deployment process is working?
Your DORA Scorecard
Track these quarterly with your engineering lead:
| Metric | Current (yours) | Target | Elite Teams |
|---|---|---|---|
| Deployment Frequency | _____ per week | Weekly | Multiple/day |
| Lead Time | _____ days | <7 days | <1 day |
| Change Failure Rate | _____% | <15% | <5% |
| Time to Restore | _____ hours | <1 hour | <15 min |
Action: Screenshot this, fill it out, and share with your team.
Post-Deployment Review (24 Hours Later)
After every major release, your team should review:
1. Did we ship on time?
2. Did everything work as planned?
3. How many issues occurred post-deployment?
4. How long did it take to detect and fix them?
5. What would we do differently next time?
This conversation makes future deployments smoother.
Your Action Plan: Start This Week
This Week (Pick ONE to start)
Option A: Planning Improvement (15 minutes)
Use the requirements template from this guide in your next sprint planning. Compare vague vs. detailed requirements with your team.
Option B: Build Visibility (5 min/day)
Ask engineering for access to your build dashboard. Bookmark it. Check it daily for 1 week. Understand your build times and failure patterns.
Option C: Deployment Strategy (10 minutes)
Ask your engineering lead: “What deployment strategy do we use for risky changes? Which features will use canary deployment?”
Document the answer.
Which will you try first? Reply in the comments. I genuinely want to know which was most useful.
This Sprint
- Attend a code review to see what engineers look for
- Understand your build pipeline (ask for a 15-minute walkthrough)
- Check your monitoring dashboards
- Review your rollback procedures
- Ask deployment strategy questions during planning
This Quarter
- Ask DevOps team to walk through a complete deployment
- Attend a post-deployment review
- Understand what incidents look like in your system
- Check your DORA metrics against industry benchmarks
- Identify one improvement to your deployment process and advocate for it
Final Thoughts
Understanding how code flows to production transforms your effectiveness as a product manager.
You stop treating deployment as a mysterious black box that “engineering handles.” You recognize it as a critical process that directly impacts every customer.
You set realistic timelines. You make smarter decisions. You earn engineering’s respect.
Most importantly, you prevent the $47K mistakes.
Key Takeaways to Remember
- Code follows a structured path: Plan → Code → Build → Test → Deploy → Monitor
- Each phase catches different issues: Tests catch bugs, staging finds integration problems, monitoring catches production issues
- Deployment strategy depends on risk: Risky features need careful strategies like canary deployments
- Your role is planning realistic timelines and making informed risk decisions
- Process maturity beats working harder: Elite teams ship 2-3x faster using better systems, not longer hours
Next Time You’re Planning a Release
Before you commit to a date, ask:
- What deployment strategy are we using and why?
- What’s our rollback plan?
- What will we monitor post-deployment?
- What could go wrong and how do we respond?
- How will we know if this was successful?
These questions separate good PMs from great ones.
Your Turn
Two questions:
Which deployment disaster have you experienced?
- Friday afternoon chaos?
- Database migration nightmare?
- “We don’t need staging” regret?
Share your story in comments (top story gets featured in next post)
Which action will you take this week? ☐ Planning improvement ☐ Build visibility ☐ Deployment strategy check
Reply with your choice and I’ll share specific tips
I read every comment and respond to all deployment questions.
This is Part 3 of the DevOps for Product Managers series.
Read the complete series:
- Part 1: DevOps for Product Managers: A Complete Guide for Non-Technical Leaders
- Part 2: How Product Managers Should Apply DevOps Knowledge (Practical Guide)
Want practical PM guides on technical leadership, feature delivery, and engineering collaboration?
Subscribe to get notified when new posts publish.